
AI摘要介绍
Umi-OCR 是一款开源免费、支持离线运行的 OCR 工具,可在无需联网的情况下完成图片与 PDF 的文字提取,有效保障用户隐私安全。
日常工作和学习中,我们经常需要把图片、PDF 里的文字提取出来 —— 付费 OCR 工具太贵、在线 OCR 担心隐私泄露、免费工具又功能残缺?今天给大家推荐一款完全开源免费的离线 OCR 神器:Umi-OCR,兼顾易用性和功能性,堪称文字识别的 “瑞士军刀”。
为什么选 Umi-OCR?核心优势一眼看穿
Umi-OCR 是由开发者 hiroi-sora 维护的开源项目,对比市面上的 OCR 工具,它的核心优势堪称 “降维打击”:
1. 完全免费 + 开源,无任何套路
Umi-OCR 遵循 MIT 开源协议,所有代码都公开在 GitHub 上,没有广告、没有付费解锁功能、没有隐藏限制,个人和商用都完全免费。你甚至可以基于源码自定义修改,满足个性化需求。
2. 离线运行,隐私与效率兼得
无需联网、无需登录账号,所有识别过程都在本地完成 —— 既不用担心图片 / 文档中的敏感信息泄露,也摆脱了网络速度的限制,识别速度完全取决于你的电脑性能,甚至比多数在线 OCR 服务更快。
3. 跨平台兼容,覆盖主流系统
最初适配 Windows7 x64 及以上版本,如今已支持 Linux x64 平台,还提供 Docker 部署方案,不管是日常办公的 Windows 电脑,还是开发用的 Linux 服务器,都能轻松用上。
4. 灵活易用,支持多场景调用
不仅有可视化的 GUI 界面,还支持命令行调用、HTTP API 接口,可以无缝集成到你的自动化脚本、业务系统中,比如批量处理文档、对接自研工具,灵活性拉满。
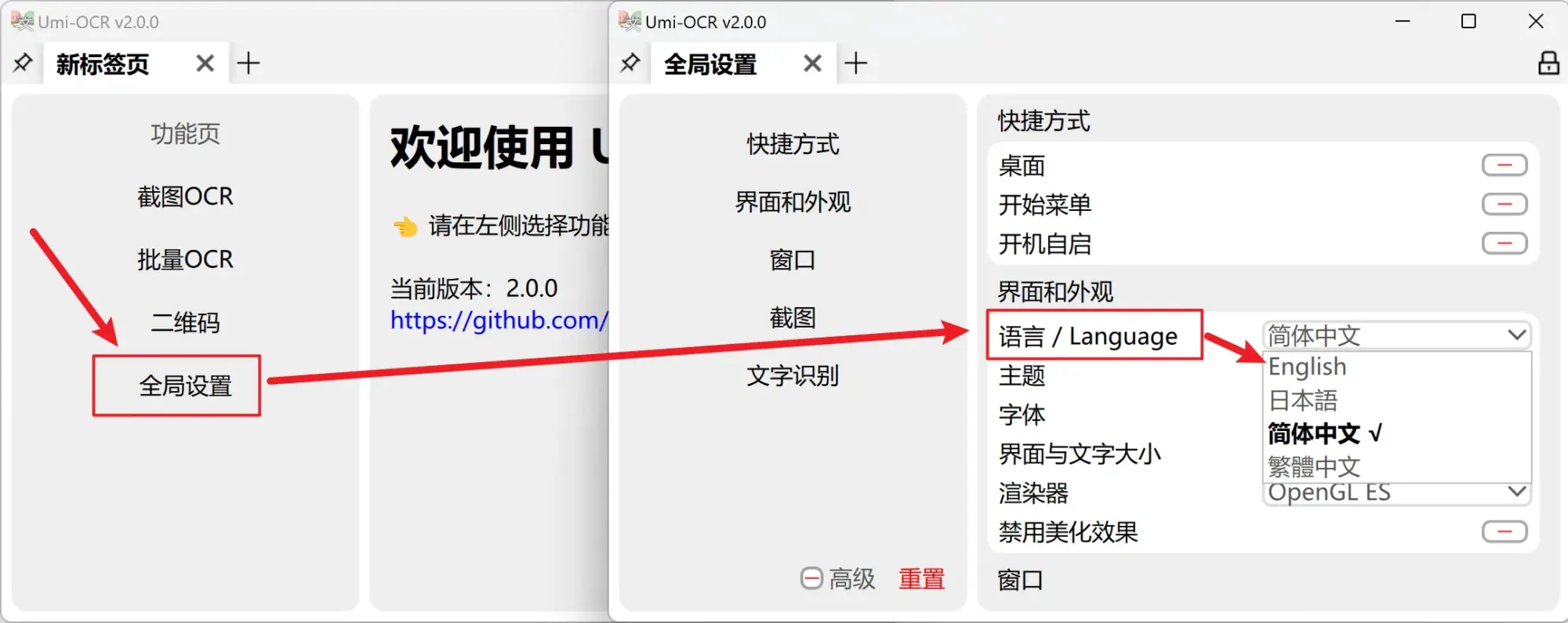
5. 多语言支持,全球化适配
界面支持简体中文、繁体中文、英语、日语、葡萄牙语等十余种语言,还通过 Weblate 平台开放本地化协作,如果你有翻译能力,还能参与到项目的多语言建设中。
Umi-OCR 核心功能:满足你所有文字识别需求
Umi-OCR 不是简单的 “图片转文字” 工具,而是覆盖全场景的文字识别解决方案:
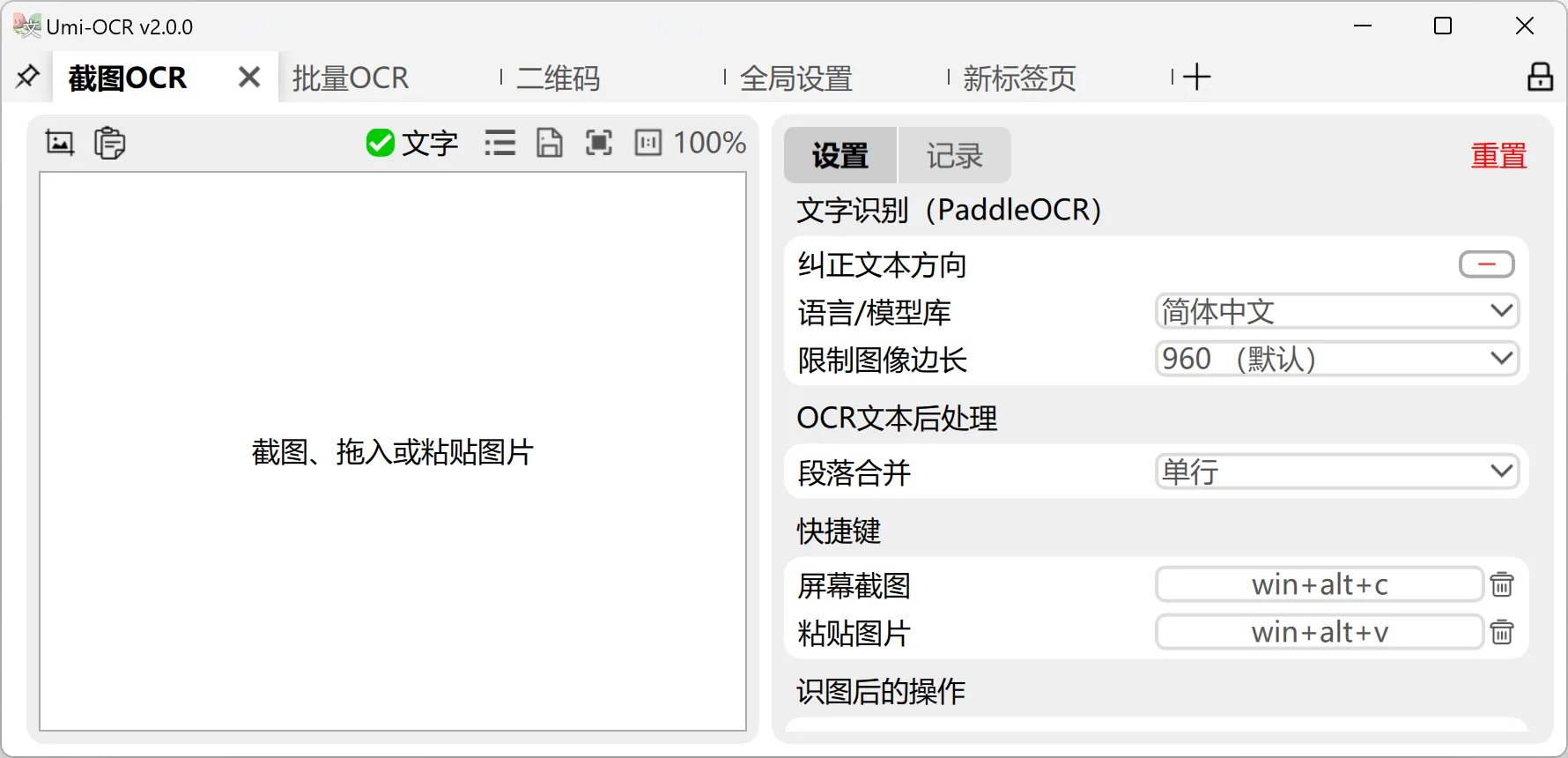
1. 截图 OCR:即截即识别,效率拉满
这是最常用的功能之一 —— 打开截图 OCR 标签页,按下自定义快捷键就能唤起截图工具,框选需要识别的区域,秒出文字结果。
- 左侧预览栏可直接划选复制文字,右侧记录栏支持编辑、批量复制;
- 支持粘贴剪贴板中的图片(比如微信 / QQ 截图)直接识别,无需保存到本地;
- 还能通过方向键微调截图框位置,Esc 键快速中断截图操作,细节拉满。
2. 批量 OCR:一次性处理海量文件
面对大量图片、PDF 需要提取文字?Umi-OCR 的批量识别功能可以批量导入文件,一次性完成识别,还支持:
- 忽略指定区域(比如水印、广告栏),避免无效文字干扰;
- 导出为 CSV 格式(兼容 Excel),方便后续整理分析;
- 排版优化:自动处理文本块格式,还原原文的段落、换行逻辑。
3. 拓展功能:不止于文字识别
Umi-OCR 还贴心适配了更多实用场景:
- 二维码 / 条形码识别:直接识别图片中的二维码、条形码内容,还支持 HTTP / 命令行调用该功能;
- 公式识别:针对数学、物理公式的识别优化(持续迭代中);
- 主题自定义:支持浅色 / 深色主题切换,还能外置主题文件定制界面风格;
- 字体切换:自定义输出栏字体,适配不同阅读习惯。
快速上手:3 步搞定 Umi-OCR
Umi-OCR 的易用性体现在 “零安装、秒启动”,哪怕是电脑小白也能快速上手:
步骤 1:下载安装
Umi-OCR 无需安装,解压即用,你可以从这些渠道下载最新版本:
- GitHub(官方):https://github.com/hiroi-sora/Umi-OCR/releases/latest
- Source Forge:https://sourceforge.net/projects/umi-ocr
- 蓝奏云(国内):https://hiroi-sora.lanzoul.com/s/umi-ocr
- Scoop(Windows 命令行安装):
Bash/Shell
# 添加extras桶
scoop bucket add extras
# 安装(Rapid-OCR引擎,兼容性高)
scoop install extras/umi-ocr
# 或安装Paddle-OCR引擎版本(速度更快)
scoop install extras/umi-ocr-paddle步骤 2:启动使用
解压后双击
Umi-OCR.exe 即可启动(Linux 系统运行 umi-ocr.sh),主界面分为多个标签页:- 截图 OCR:快捷键唤起截图,实时识别;
- 批量 OCR:导入文件,一键批量识别;
- 二维码识别:解析图片中的二维码 / 条形码;
- 设置:自定义快捷键、输出格式、界面语言等。
步骤 3:进阶使用(可选)
如果需要集成到自动化流程中,可以尝试:
- 命令行调用:支持指定图片路径、输出结果到文件、切换识别语言等指令;
- HTTP 接口:通过 API 调用 OCR、二维码识别功能,文档参考:https://github.com/hiroi-sora/Umi-OCR/blob/main/docs/http/README.md。
开源生态:Umi-OCR 的持续进化
Umi-OCR 之所以能持续迭代,离不开开源社区的支持:
- 开发计划透明:作者在仓库中公开了已完成和待开发的功能,比如 PDF 识别优化、Linux 平台适配等都已落地;
- 本地化协作:通过 Weblate 平台开放翻译协作,已有多位译者贡献了英语、日语、繁体中文等语言的翻译;
- 插件拓展:支持 OCR 引擎插件(如 PaddleOCR-json、RapidOCR-json),可按需切换引擎,兼顾速度和准确率;
- 问题反馈:GitHub Issues 通道开放,作者会及时响应 Bug 反馈和功能建议,甚至还支持通过爱发电赞助项目开发。
总结:一款值得收藏的 OCR 神器
不管是学生党提取课件文字、职场人处理办公文档,还是开发者集成 OCR 功能到项目中,Umi-OCR 都能完美适配 —— 免费、开源、离线、高效,还兼顾了易用性和拓展性,堪称 “无短板” 的 OCR 工具。